

 Tweet
Tweet
 Share
Share
はじめに
初めまして、サーバーサイドエンジニアの曽根田です。
での紹介にもあるように、弊社では複数のマンガアプリの開発が並行して進められています。
その中で今回はマンガZEROの成長過程でぶつかり、
乗り越えてきた問題をサーバーサイド視点で紹介していきたいと思います。
乗り越えてきた問題
最初はPHP5.6+Phalconというマイクロフレームワークでプロダクトを運用していました。
マンガZEROメジャーバージョンのアップデートの際に、golangを採用しました。
理由は以下の2点です。
- バイナリ一つで動作する(外部依存しない)
-
軽量でハイパフォーマンス
弊社には積極的に新しい技術や言語を採用しようという文化があるので、
いち早く情報をキャッチアップしたいというのも採用理由のひとつです。
リリース当初は問題なく動作していたのですが、マンガZEROが大きく成長し始めた2017年あたりから以下の問題にぶつかりました。
- メモリリーク
-
CPU負荷の増大
-
アプリケーションとキャッシュサーバー間のパーフォマンス問題
-
マスターDB/スレーブDB間のレプリカラグの増大
-
ログデータの肥大化
今回はそれぞれ私たちが対応してきた内容を公開します。
使用言語、ミドルウェアは以下を使用しています
使用言語&ミドルウェア
- golang(1.8)
-
Nginx(1.10)
-
Redis(Amazon ElastiCache)
-
Mysql(Amazon Aurora)
どうやって乗り越えてきたか
アプリケーションのチューニング
[ goroutine使用箇所の洗い出しと使用頻度の軽減 ]
golang標準パッケージnet/httpを使用してアプリケーションサーバーを動かしています。
標準パッケージ内の起動スクリプト箇所では全てのリクエスト処理に対して、
goroutineを起動させて並列処理を行っています。
以下のnet/http内のサーバー起動プログラムを見てみるとリクエストを受け取るごとにgoroutineを起動させています。
func Serve(l net.Listener, handler http.Handler) error {
if l == nil {
var err error
l, err = net.FileListener(os.Stdin)
if err != nil {
return err
}
defer l.Close()
}
if handler == nil {
handler = http.DefaultServeMux
}
for {
rw, err := l.Accept()
if err != nil {
return err
}
c := newChild(rw, handler)
go c.serve()
}
}
golangの特徴でもある、並列・並行処理なのですが、以下の特徴があります。
- goroutineの起動にもコストがかかってしまうこと
- コストがかさむと雪だるま式にパフォーマンスが劣化してしまうこと
これらの特徴を考えると、goroutineの扱いは慎重にならなければなりません。
まず前段のnginxではworker_connectionsを2048に設定しています。
そのため、それ以上のconnectionは発生しないものの、goroutine起動コストなどを考慮し、
golang.org/x/net/netutilパッケージを利用することで、最大接続数を1024に設定しました。
またアプリケーションのロジック内で行っている並列・並行処理は極力行わないように修正しました。
goroutineの起動にも少なからずコストがかかることを考えると、
並列化させる処理が重たい処理ではない限り、シーケンシャルに処理した方が安定して処理してくれます。
個人的にgolangでは、バッチやミドルウェアの開発以外では、goroutineは使う必要がないのかなという感覚を持っています。
気軽に並列・並行処理を行えるのは魅力的ですが、goroutineを扱う際は慎重になることをお勧めします。
[ slice使用時の初期化の際にサイズを割りあてる ]
当たり前のことかもしれないですが、軽量プログラミング言語で育ってきた私のようなエンジニアにとっては割と盲点になりがちです。
ベンチマーク用のコード
package main
import (
"testing"
)
func BenchmarkAppend(b *testing.B) {
for i := 0; i < b.N; i++ {
slice := []string{}
for i := 0; i < 1000; i++ {
slice = append(slice, "test")
}
}
}
func BenchmarkAppend2(b *testing.B) {
for i := 0; i < b.N; i++ {
slice := make([]string, 1000)
for i := 0; i < 1000; i++ {
slice[i] = "test"
}
}
}
ベンチマーク結果
BenchmarkAppend 200000 10218 ns/op 32752 B/op 11 allocs/op
BenchmarkAppend2 1000000 1262 ns/op 0 B/op 0 allocs/op
結果は明白です。
あらかじめ配列の大きさがだいたい予想できるのであれば、少し大き目に容量を確保してあげることでパフォーマンスの劣化を防ぐことができます。
タイムアウト設計の見直し
マンガZEROの成長期に特に頻発した問題が、アプリケーションサーバー/キャッシュサーバー間のパフォーマンス問題です。
この問題はアクセス数がある程度増大するまで、表面的に問題とならないのが厄介でした。
当初の各ミドルウェア周りのタイムアウトの設定は下記の状態でした。
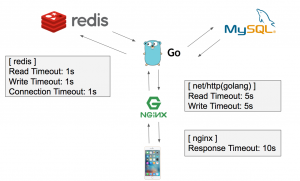
設計上、1リクエストで複数回キャッシュサーバーにアクセスし、データを取得するようなアプリケーションになっています。
キャッシュサーバーのタイムアウト期間を長く設定しすぎたため、アプリケーションサーバー/Webサーバー間でタイムアウトが発生した場合でも、アプリケーションサーバー/キャッシュサーバー間のやり取りは死んでいない状態になってしまっていました。
そのため、アクセス数が多い高負荷時にアプリケーションサーバー/キャッシュサーバー間との接続やデータの読み込みに遅延が発生してしまうと、アプリケーションサーバー/Webサーバー間でタイムアウトエラーが発生してしまいます。
この状態でクライアント側からのリクエストのリトライが行われることで、アプリケーションサーバー/キャッシュサーバー間のやり取りが雪だるま式に積もっていき、パフォーマンスを劣化させてしまうという状況でした。
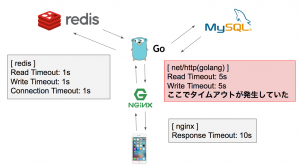
そこで全体的なタイムアウト設計を見直したのですが、特にキャッシュサーバー側でのタイムアウト時間を短めに設定しました。
遅くとも340ms以内にキャッシュサーバーからレスポンスが返ってこない場合は、MySQLへデータを取得しにいく設計に修正しました。
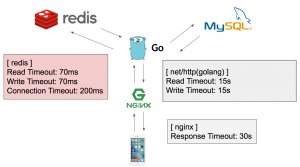
こうすることでアプリケーションサーバー/キャッシュサーバー間でコネクションが詰まることを防ぐことができ、パフォーマンス劣化が生じにくいタイムアウト設計になりました。
DBテーブルのIndex見直しとslow query改善
開発の初期段階では開発スピードを優先していたため、この辺りの基本的なチューニングや設計がおろそかになっていました。
そのため、サービスの成長とともに問題が表面化され、大きいボトルネックとなってしまっていました。
- データ量が肥大化しすぎ、テーブルへの変更に数時間かかってしまう
- その為、半日以上のメンテナンス時間が必要になってしまう
- 影響範囲が大きく調査に時間がかかる
こういったプロダクトの経験から、最低限以下のことには細心の注意を払う文化がチーム全体で生まれました。
- どの程度の量のデータが想定されるか
- そのデータはどのように使用される可能性があるのか
- 使用用途に合わせて適切に設計されているか
当たり前のことかもしれないですが、どんなにスモールスタートのプロダクトでも、
上記のようなことは常に頭に入れて開発に入ることが重要だと痛感しました。
Amazon RDS から Amazon Auroraへ移行
Amazon Auroraへ移行したきっかけは以下の2点で問題を抱えていたからです。
- ログデータの肥大化
- 致命的なレプリケーションラグの発生
ログデータの肥大化についてですが、基本的に弊社ではログデータはある程度の期間を区切って、AmazonS3へ定期的にバックをとっています。
しかし、マンガZEROの成長に伴い、期間内のデータが毎月増大する傾向にありました。
- 日々RDSのストレージの残容量を気にしなければならない
- ストレージ残量が少なくなってきたらメンテナンスを入れてストレージの容量を増やさなければならない
Amazon Auroraであれば自動スケールしてくれるので、この問題を気にしなくてよくなります。
また致命的なレプリケーションラグの発生ですが、Amazon Auroraはマスターとレプリカ間でストレージを共有してくれるため、ほぼレプリケーションラグが発生しません。
アプリケーション設計の問題もあるのですが、この時点ではアプリケーション改修作業にかかるコストと天秤にかけて、 Amazon Auroraへ移行することにしました。
最後に
現状全ての問題が解決したわけではありませんが、安定してサービスの提供ができている状態です。
安定面で現状残っている社内の大きな課題として
- サーバー監視体制の強化
があります。
こちらは最近メンバーに加わった若さ以上に場数を踏んできているインフラエンジニア
が「Prometheus」「Grafana」を使用した監視体制の構築をゼロから進めてくれています。
また、より高速にサービス成長を加速させるためのマンガZEROプロジェクトの動きとしては
- 日々のグロース施策の開発効率をあげること
- コンテンツ管理ツールの運用効率をあげること
- データ分析基盤の構築
などが並行して進んでいます。
「日々のグロース施策の開発効率をあげること」
「コンテンツ管理ツールの運用効率をあげること」
に関しては、
- コンテンツ管理ツールのような機能拡張頻度の高いアプリケーションの開発効率をあげること
- サーバーチーム全体で素早く安定したアプリケーションの機能拡張を行える環境を作ること
が求められています。
パフォーマンス面を理由で採用されたgolangですが、開発効率に重点を置く場合にはPHPでの開発・運用を積極的に取り入れるようにしています。
理由は以下の3点です。
- PHPのパフォーマンスがバージョン7で大幅に改善されたこと
- 運用面を考えるとPHPにメリットがあること
- PHPに関する社内ノウハウが豊富なこと
また「データ分析基盤の構築」に関しては、先ほど紹介させていただいた若きインフラエンジニアが、ログ分析の基盤の構築や「ElasticSearch」「Kibana」の導入を検証してくれているところです。
マンガZEROをもっと成長させる為にまだまだサーバーサイドのエンジニアが必要です。
もし弊社のブログを見て興味を持っていただいた方は1度弊社に遊びにきてください。
また、他のブログ記事に目を通していただければ、弊社の雰囲気がもっと伝わるかと思います。
今回は最後まで私のブログに目を通していただきありがとうございました。