

 Tweet
Tweet
 Share
Share
どうもNagisaでインフラエンジニアをしております榎戸です。
今回は下記記事の続編ということで
実際にPrometheusのインストールや設定について書いて行こうと思います。
※2017-10-05にv2.0.0-rc.0がリリースされておりましたので
v2.0.0-rc.0を使用して説明を行なっていきます。
また光栄な事に意外と反響が大きく、こういうことを知りたいなどのコメントを頂けたので
その辺りはまた次回以降に書かせて頂こうと思っております。
今回紹介する内容
- 導入
-
Prometheusインストール
-
node_exporterインストール
-
AWS/EC2インスタンスの絞り込み
-
グラフの表示
-
お知らせ
また思っていたより記事が長くなりそうなので、何回かに分割して記事を書いていくことにします。
それでは今回も宜しくお願いします。
導入
監視を行う上で必ずと言っていい程、監視ツールを使用するかと思われます。
そんな監視ツールには監視を行う際に情報をどのように取得するか、という型があります。
主に2つの型があると言われておりPull型とPush型と言われています。
- Pull型
- 監視を行うサーバが監視対象のサーバへメトリクスを取得しに行く
- Push型
- 監視対象のサーバが監視を行うサーバへメトリクスを渡す
どちらにもメリット、デメリットが存在するので、一概にどちらがいいと言える訳ではありません。
- pull型
メリット :関係のないサーバからのメトリクスを受け付けない
デメリット :監視を行うサーバが増えた際に監視サーバ本体の設定変更が必要 -
push型
メリット :監視を行うサーバが増えても監視サーバ本体の設定を変更しなくても良い
デメリット :監視対象ではないサーバがメトリクスを投げても受けてしまう
しかしPrometheusはPull型を採用しておりますが、pull型のデメリットの部分(監視を行うサーバが増えた際に監視サーバの設定変更が必要)をService Discoveryという、サーバを自動で検知してくれる仕組みが補ってくれているので、監視サーバの設定の変更はほとんど必要ありません。
つまりPrometheusはpull型のデメリットである部分をほとんど払拭しております。
今回はPrometheusで自動検知を行い、実際にグラフが表示されるまでを記事にしました。
Prometheusインストール
それではPrometheusのインストールを行なっていきます。
今回は実際にPrometheusの画面を表示してメトリクスの確認まで行いたいと思います。
また弊社ではAmazon Linuxを使用しておりますのでCentOS6の環境を参照して構築しました。
構成としては下記となっております。
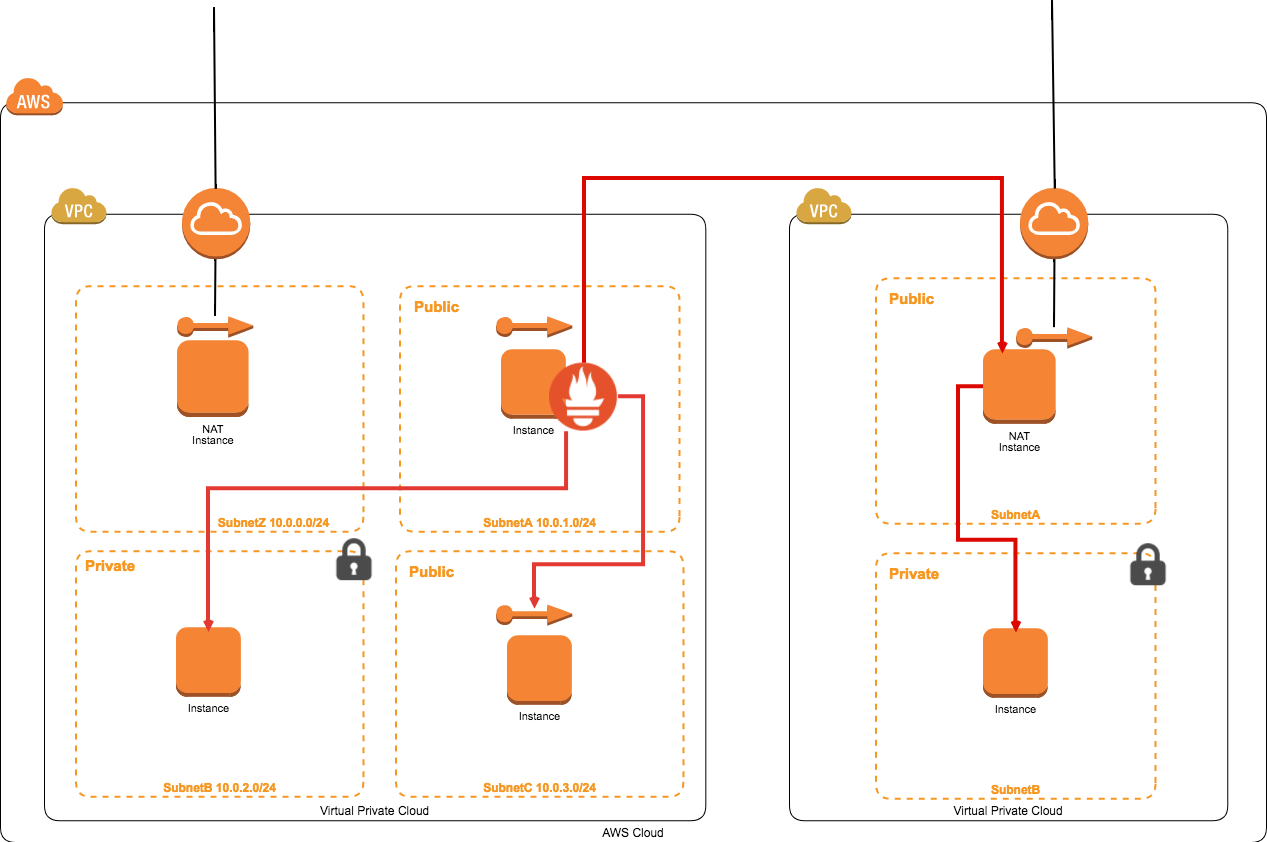
- Prometheus公式:
https://prometheus.io/download/ - v2.0.0-rc.0 Github:
https://github.com/prometheus/prometheus/releases/tag/v2.0.0-rc.0
・本体のインストール
$mkdir /usr/local/src/prometheus
$cd /usr/local/src/prometheus
$wget https://github.com/prometheus/prometheus/releases/download/v2.0.0-rc.0/prometheus-2.0.0-rc.0.linux-amd64.tar.gz
$tar zxvf prometheus-2.0.0-rc.0.linux-amd64.tar.gz
$cd prometheus-2.0.0-rc.0.linux-amd64
$cp -ip prometheus.yml prometheus.yml.org
とりあえず、ここまででPrometheus本体を起動できるようになりましたので
下記コマンドにて起動してみましょう。
$./prometheus -config.file=prometheus.yml
ちなみに、ここまではPrometheusの公式ページにて確認することができますので、合わせてご確認下さい。
- Prometheus公式:
https://prometheus.io/docs/introduction/getting_started/
あれ・・・起動できない・・・
2系を導入した際、最初にここで躓きました・・・
では、なぜ起動できないかというと
実はPrometheus 2.0 Alpha.3以降、ルールの変更がありました。
”First, we moved to a new flag library, which uses the more common double-dash -- prefix for flags instead of the single dash Prometheus used so far.”
との記載があります。
つまり
NG: ./prometheus -config.file=prometheus.yml OK: ./prometheus --config.file=prometheus.yml
となります。
それでは気を取り直して
$./prometheus --config.file=prometheus.yml
これで起動できましたね。
ブラウザでhttp://x.x.x.x:9090と叩くと、下記のような画面が表示されると思います。
AWSのセキュリティグループで制限を行なっている方は、9090番ポートを開けてからお試しください。
またhttp://x.x.x.x:9090/metricsと叩くと、下記のような画面になります。
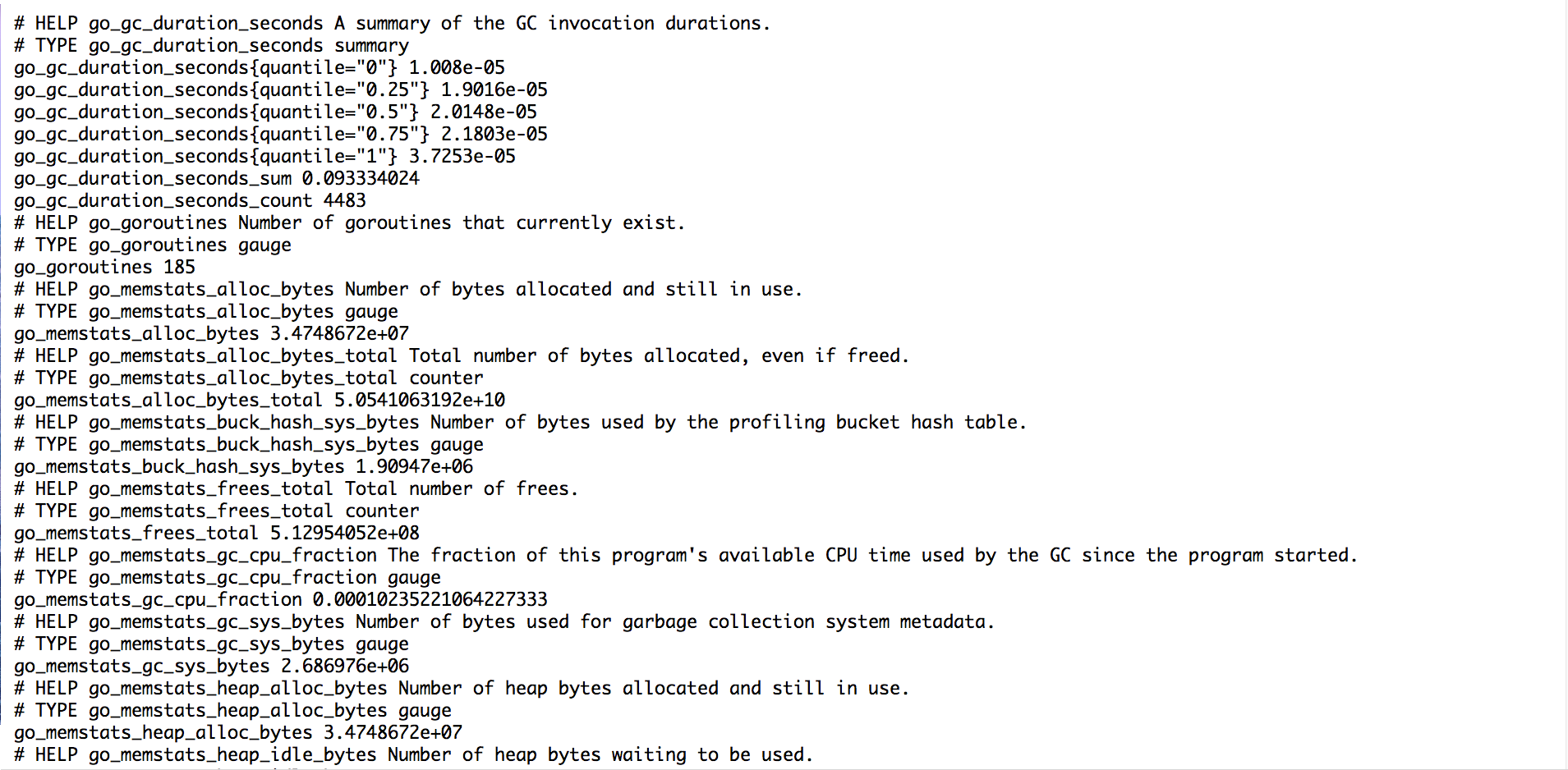
これがPrometheusのメトリクスとなっております。
メトリクスについては後ほど。
以上でPrometheus本体のインストールは完了となります。
次の項目ではPrometheusのエージェントとなる
node_exporterを監視対象のインスタンスにインストールしていきます。
node_exporterインストール
それでは監視対象サーバにnode_exporterをインストールしていきます。
監視対象のサーバにログインして下記を行なってください。
またnode_exporterについては下記の公式よりインストールを行なっています。
- Prometheus公式:
https://prometheus.io/download/
・インストール
$mkdir /usr/local/src/node_exporter
$cd /usr/local/src/node_exporter
$wget https://github.com/prometheus/node_exporter/releases/download/v0.15.0/node_exporter-0.15.0.linux-amd64.tar.gz
$tar zxvf node_exporter-0.15.0.linux-amd64.tar.gz
$cd node_exporter-0.15.0.linux-amd64
ここまできたらnode_exporterのインストールは完了です。
下記コマンドにて起動してください。
$./node_exporter
起動をしたら先ほどのPrometheus本体と同様ブラウザで確認していきましょう。
http://x.x.x.x:9100/metrics
今度は9100番ポートになっておりますのでご注意下さい。
またAWSを使用している方はPrometheusサーバからの接続が通るように
セキュリティグループを設定しておきましょう。(9100番ポート解放)
下記のようにメトリクスが表示されます。
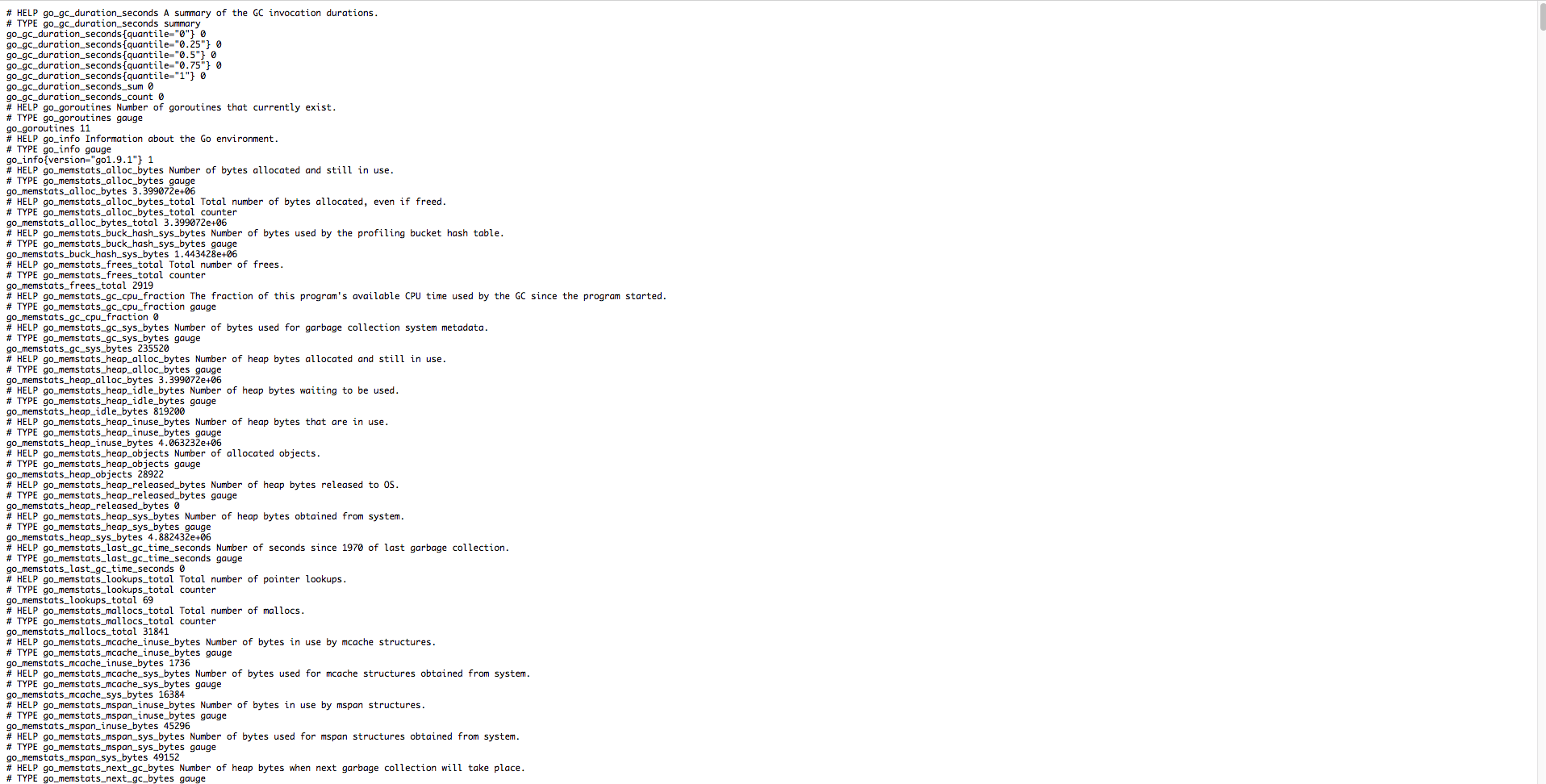
これらのメトリクスは、デフォルトで取得するもの、しないものが決まっています。
その内容については下記に記載されております。
- node_exporter Git:
https://github.com/prometheus/node_exporter
また上記については
$node_exporter --help
でも確認することができます。
またnode_exporterのバージョン0.14.0 までは
node_exporter
--collectors.enabled="A,B,C"
のように指定することができました。
例えば下記のような感じです。
$node_exporter --collectors.enabled="conntrack,diskstats,entropy,filefd,filesystem,loadavg,mdadm,meminfo,netdev,netstat,stat,textfile,time,vmstat"
今回インストールを行なったnode_exporter-0.15.0については上記指定では起動できなくなっており下記のような形で指定するようです。
- job_name: 'node storage'
scrape_interval: 1m
static_configs:
- targets:
- '192.168.1.2:9100'
params:
collect[]:
- filefd
- filesystem
- xfs
以上でnode_exporterのインストールは完了となります。
ここまででPrometheus本体のインストールと監視対象サーバへのnode_exporterのインストールが終わりました。
次項ではPrometheus本体から監視対象サーバへ値を取得しにいき、グラフを表示したいと思います。
AWS/EC2インスタンスの絞り込み
これからPrometheusの設定を行なっていきます。
詳しいことを記載しすぎると、とても長くなってしまうので
詳しい設定については下記にてご確認をお願い致します。
- Prometheus公式:
https://prometheus.io/docs/operating/configuration/
Prometheusサーバにて
$cd /usr/local/src/prometheus/prometheus-2.0.0-rc.0.linux-amd64
$vi prometheus.yml
・prometheus.ymlデフォルト
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).# Attach these labels to any time series or alerts when communicating with
# external systems (federation, remote storage, Alertmanager).
external_labels:
monitor: ‘codelab-monitor’# Load rules once and periodically evaluate them according to the global ‘evaluation_interval’.
rule_files:
# – “first.rules”
# – “second.rules”# A scrape configuration containing exactly one endpoint to scrape:
# Here it’s Prometheus itself.
scrape_configs:
# The job name is added as a label `job=` to any timeseries scraped from this config.
– job_name: ‘prometheus’# metrics_path defaults to ‘/metrics’
# scheme defaults to ‘http’.static_configs:
– targets: [‘localhost:9090’]
デフォルトのままなので上記のような状態になっているかと思われます。
先にもお伝えしたように今回はAWSにて設定を進めていきますのでご了承ください。
Prometheus では relabel_configs でインスタンスの設定タグを絞る方法があります。
例えば3台のインスタンスがありそれぞれ下記のように設定しているとします。
そしてこの中のserver1の監視を行いたいとします。
・server1
- キー
- 値
- Name
- server1
- environment
- prod
- project
- nagisa
・server2
- キー
- 値
- Name
- server2
- environment
- stg
- project
- nagisa
・server3
- キー
- 値
- Name
- server3
- environment
- prod
- project
- hogehoge
このような時にまずキーがprojectで値がnagisaのもので絞り込みます。
そうすることでserver1,server2にまず絞り込むことができます。
次にキーがenvironmentで値がprodのもので絞り込みます。
これでserver1に絞り込みができました。
それでは上記の絞り込みで実際の設定を追加していきます。
- job_name: 'monitor'
ec2_sd_configs:
- region: ap-northeast-1
access_key: xxxxxxxxxxxxxxxxxxxx
secret_key: xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
port: 9100
relabel_configs:
- source_labels: [__meta_ec2_tag_project]
regex: nagisa
action: keep
- source_labels: [__meta_ec2_tag_environment]
regex: prod
action: keep
上記で行なっていることは
- job_name: プロジェクト名やサービス名
ec2_sd_configs: AWS/EC2の定義
- region: リージョン名
access_key: アクセスキー
secret_key: シークレットキー
port: 監視対象サーバにインストールしたnode_exporterのポート
relabel_configs: ラベルの定義
- source_labels: [__meta_ec2_tag_タグキー]
regex: 値
action: 絞り込んだラベルの維持
- source_labels: [__meta_ec2_tag_タグキー]
regex: 値
action: 絞り込んだラベルの維持
となっております。
・流れ
job_nameで任意のプロジェクト名等を記載
↓
source_labels: [__meta_ec2_tag_タグ名]でAWSのEC2につけたプロジェクトのタグを絞り込み
↓
action: keepでその絞り込みを維持したまま下に
↓
source_labels: [__meta_ec2_tag_タグ名]を記載して更にAWSのEC2につけた環境で絞り込み
上記みたいな感じで大きいところから徐々に絞り込んでいます。
またアクセスキーについては下記を参考に設定ください。
設定が完了したら下記コマンドで確認を行いましょう。
promtoolについてはhelpコマンドで確認してみて下さい。
主にconfのチェックやruleのチェックに使用するものとなります。
$./promtool check config prometheus.yml
問題がなければprometheusの再起動を行なってください。
下記画像のように表示されていれば問題ありません。
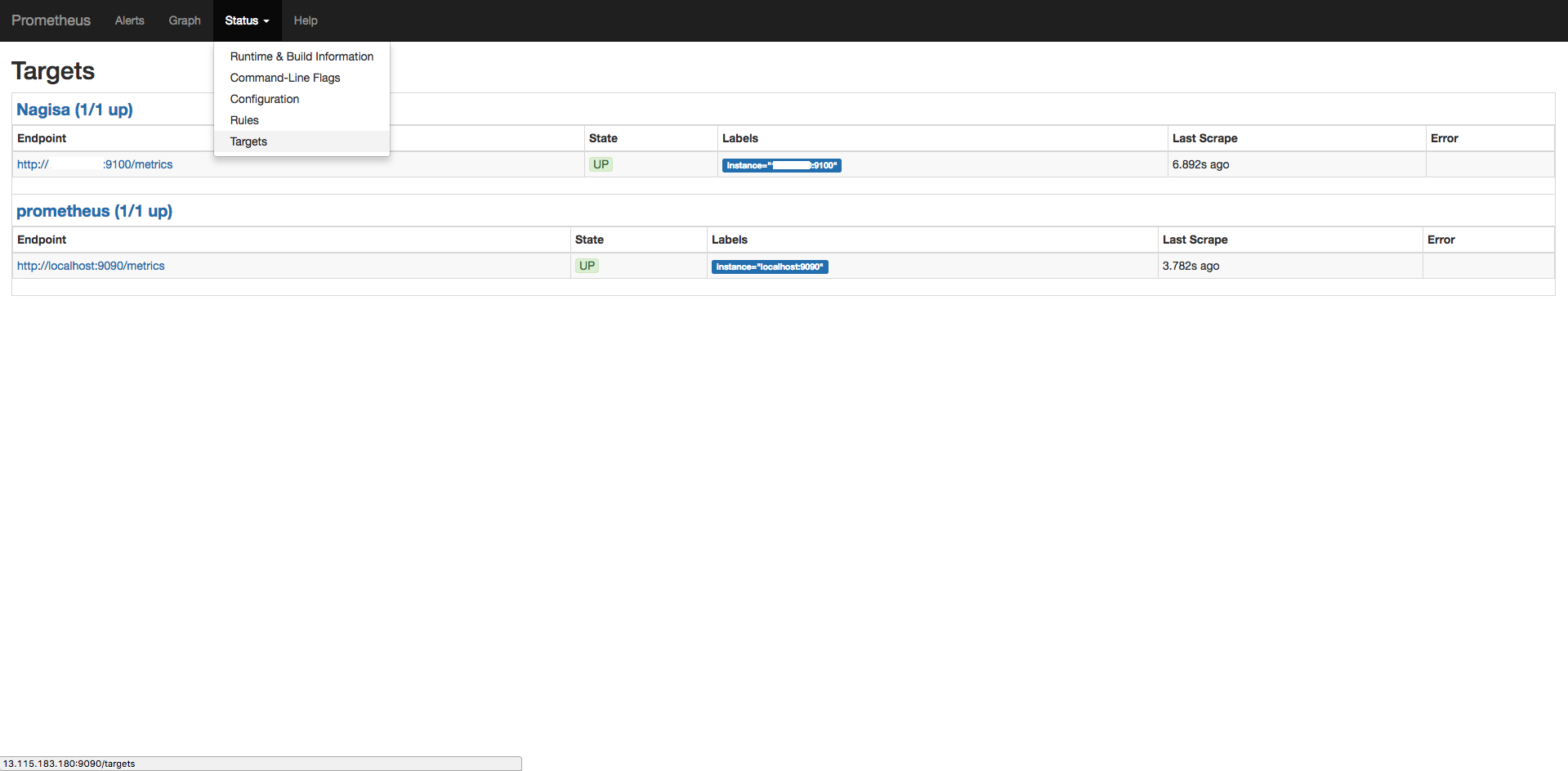
これでオートスケールでインスタンスが増えても
監視対象サーバにnode_exporterをインストールした状態であれば
上記の絞り込みで自動検知してくれるのでとても便利です。
また本記事ではご紹介できませんが、source_labels(ラベルを取ってくる先)には
他にも下記のように設定できる項目がたくさんあります。
AWSだけでこれだけあります・・・
__meta_ec2_availability_zone: the availability zone in which the instance is running __meta_ec2_instance_id: the EC2 instance ID __meta_ec2_instance_state: the state of the EC2 instance __meta_ec2_instance_type: the type of the EC2 instance __meta_ec2_private_ip: the private IP address of the instance, if present __meta_ec2_public_dns_name: the public DNS name of the instance, if available __meta_ec2_public_ip: the public IP address of the instance, if available __meta_ec2_subnet_id: comma separated list of subnets IDs in which the instance is running, if available __meta_ec2_tag_: each tag value of the instance __meta_ec2_vpc_id: the ID of the VPC in which the instance is running, if available
それでは上記の中の1つを使ってみて他の場合も行なってみます。
EC2インスタンスの監視を行う際、Prometheusはデフォルトで
プライベートIP、ポートで検出を行います。
今回はプライベートIPではなくパブリックIPにて検出を行なってみたいと思います。
行う設定は下記となります。
relabel_configs:
- source_labels: [__meta_ec2_public_ip]
regex: '(.*)' #これがデフォルト値です。
target_label: __address__
replacement: '${1}:9100' #ポートも指定する必要があります。
- source_labels: [__meta_ec2_tag_Name]
target_label: instance
上記を先ほどのタグ指定で検出する方法の前に入れる事で
プライベートIPではなくパブリックIPで検出できるようになります。
今回参照させていただいたのは下記となります。
– Robust Perception:
https://www.robustperception.io/controlling-the-instance-label/
またラベルについて詳しく知りたい方は下記を参照していただくと良いかと思います。
– Robust Perception:
https://www.robustperception.io/life-of-a-label/
またPrometheusはAWSだけでなく他にも様々な環境に使うことができますので
公式ページで確認を行なってみてください。
- Prometheus公式:
https://prometheus.io/docs/operating/configuration/
グラフの表示
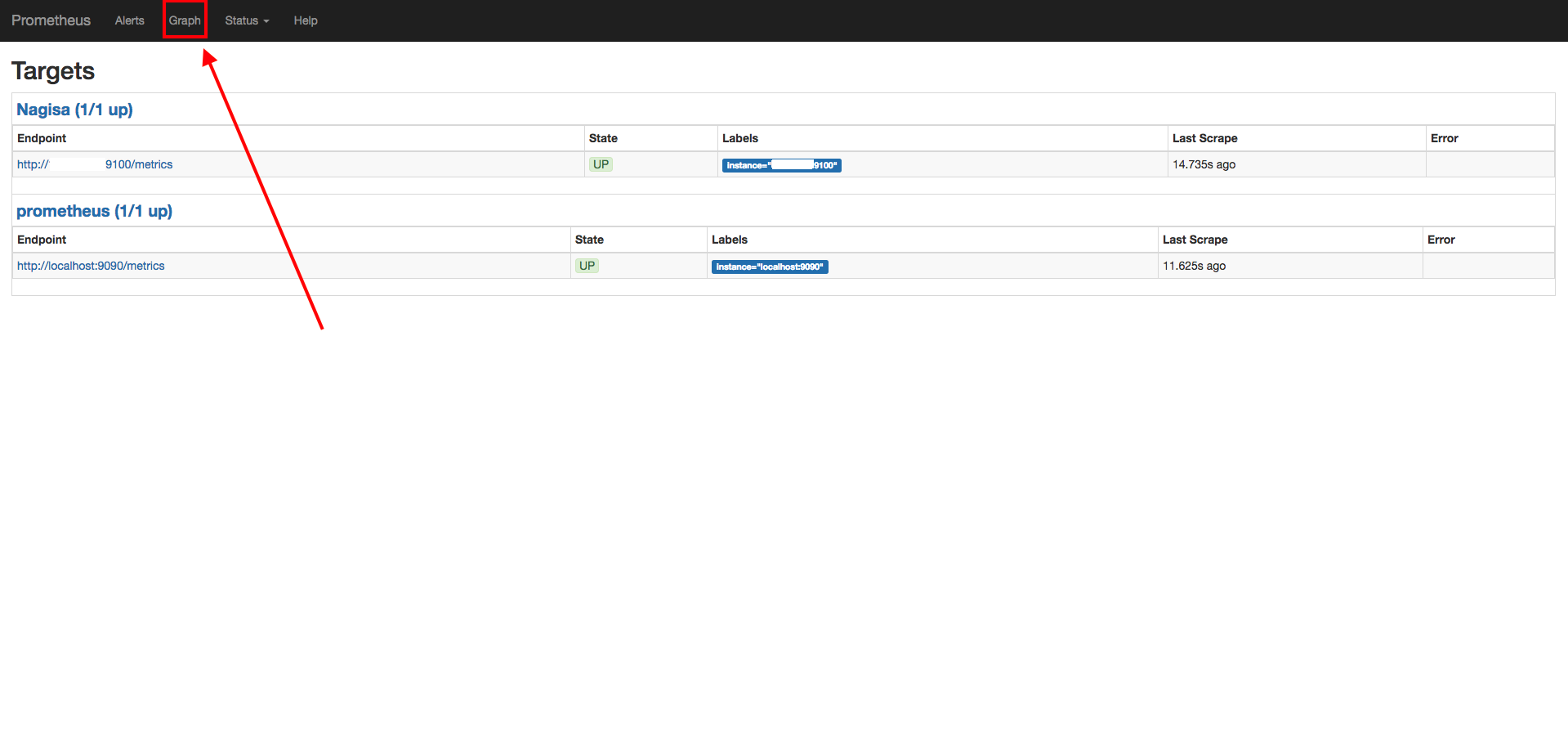
それではPrometheusを使用してグラフの表示を行なってみましょう。
下記画像に従いGraphのページに行ってください。
次にinsert metric at cursorをクリック
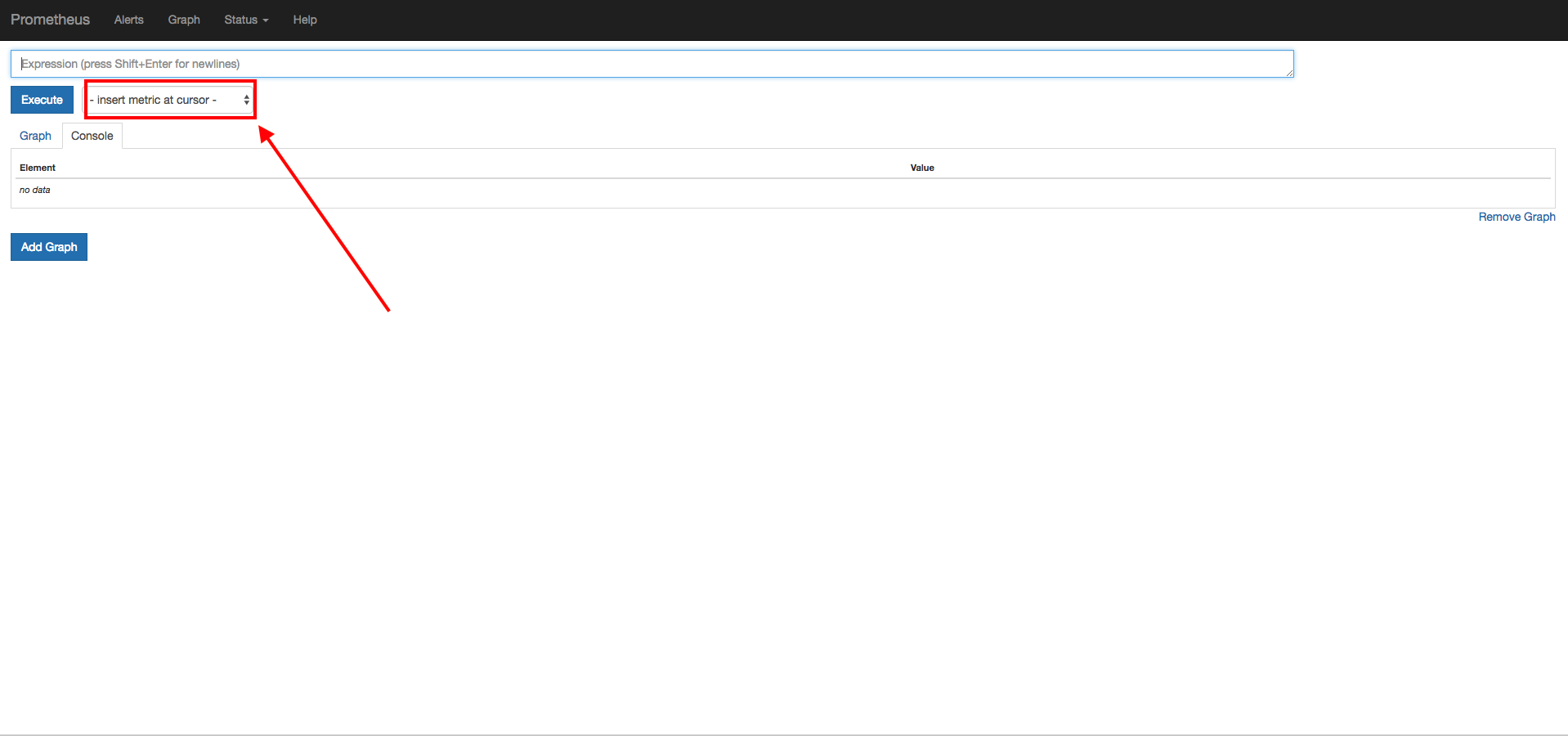
そうすると各種クエリが表示されるので
node_cpuを選択してください。
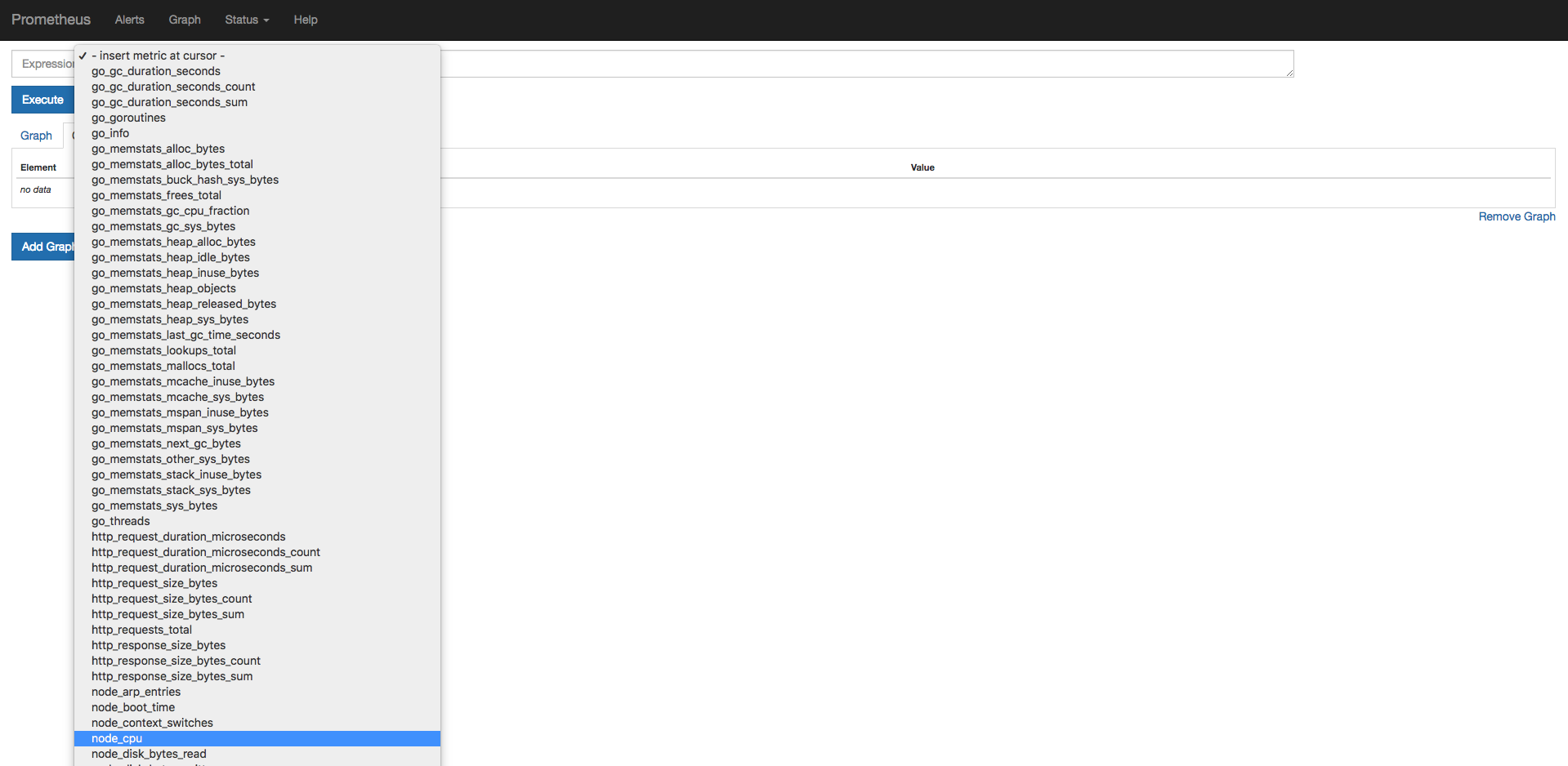
Executeをクリック
そうすると2つのタブに分かれているかと思います。
- Cosole
Cosoleのタブでは下記のようにnode_cpuのクエリでどのように取得されているのか確認できます。
node_cpu{cpu=”cpu0″,instance=”x.x.x.x:9100″,job=”Nagisa”,mode=”guest”} 0
node_cpu{cpu=”cpu0″,instance=”x.x.x.x:9100″,job=”Nagisa”,mode=”guest_nice”} 0
node_cpu{cpu=”cpu0″,instance=”x.x.x.x:9100″,job=”Nagisa”,mode=”idle”} 92659.06
node_cpu{cpu=”cpu0″,instance=”x.x.x.x:9100″,job=”Nagisa”,mode=”iowait”} 7.77
node_cpu{cpu=”cpu0″,instance=”x.x.x.x:9100″,job=”Nagisa”,mode=”irq”} 0
node_cpu{cpu=”cpu0″,instance=”x.x.x.x:9100″,job=”Nagisa”,mode=”nice”} 2.8
node_cpu{cpu=”cpu0″,instance=”x.x.x.x:9100″,job=”Nagisa”,mode=”softirq”} 0.19
node_cpu{cpu=”cpu0″,instance=”x.x.x.x:9100″,job=”Nagisa”,mode=”steal”} 5.99
node_cpu{cpu=”cpu0″,instance=”x.x.x.x:9100″,job=”Nagisa”,mode=”system”} 13.59
node_cpu{cpu=”cpu0″,instance=”x.x.x.x:9100″,job=”Nagisa”,mode=”user”} 70.87
例えば複数台のサーバがこの時点で当てはまってしまった場合でも
下記のようなクエリを再度叩くと絞り込んで表示することができます。
node_cpu{job=”Nagisa”}や
node_cpu{instance=”x.x.x.x:9100″}など
- Graph
Graphのタブではグラフが表示されます。
例えばメモリの空き容量であれば
node_memory_MemFree

メモリの使用量を知りたい場合は計算を行うので
node_memory_MemTotal – node_memory_MemFree
となります。
ここの表示については自分で色々入力したり選択したりする方が
使い方に慣れるかと思いますので是非色々なグラフを表示してみてください。
またPrometheusでのグラフ表示に慣れてしまえば
次回以降に紹介させて頂く予定のGrafanaでの表示や
alertmanagersによるアラートの閾値の設定が楽になります。
グラフの表示については以上となります。
また間違っている箇所やこうした方がいい!みたいなご意見等あれば是非宜しくお願い致します。
お知らせ
次回以降のお知らせとなります。
最初に本記事で記載させて頂こうと思っていた下記
- Prometheus、alertmanager、node_exporterのinit-script
-
alertmanagerでの通知先の設定(サービス単位での通知の振り分け)
-
Grafanaを使った描画(CloudWatch)
そして前回記事のはてなブックマークにコメントを頂きました
- NAT越しの監視
-
ログの保存期間について
等をご紹介できればと思います。
しかし量が多くなってしまうため
次回以降も何回かに分けさせていただくかと思いますが
何卒宜しくお願い致します。