

 Tweet
Tweet
 Share
Share
PrometheusでNATを越えよう!!
どうもNagisaのインフラエンジニア 榎戸です。
ついに、Prometheus2.0がリリースされました!
もっとPrometheusユーザが増えてくれると
色々な記事が上がったりして情報が増えるので嬉しいのですが・・・
今回も下記記事の続編ということで
PrometheusのNAT越えについて書いていきます。
こちらはよく個人的に聞かれたり、
多くの人が気になっているところではないでしょうか。
1万台のサーバを監視できると話題のPrometheusをGrafanaと組み合わせて導入した話
1万台のサーバを監視できると話題のPrometheusをGrafanaと組み合わせて導入した話~vol2~
また毎回記事が長すぎる気がしてきたので
これからは少し短めにして、内容を絞っていきたいと思います。
今回紹介する内容
- PrometheusでNAT越え監視
-
PushProx概要
-
PushProxインストール
-
PushProx設定
-
お知らせ
それでは今回も宜しくお願いします。
PrometheusでNAT越え監視
今回の内容としては
違うネットワークにいる、しかもlocalIPしか持っていないサーバって
どうやって監視するの?という話です。
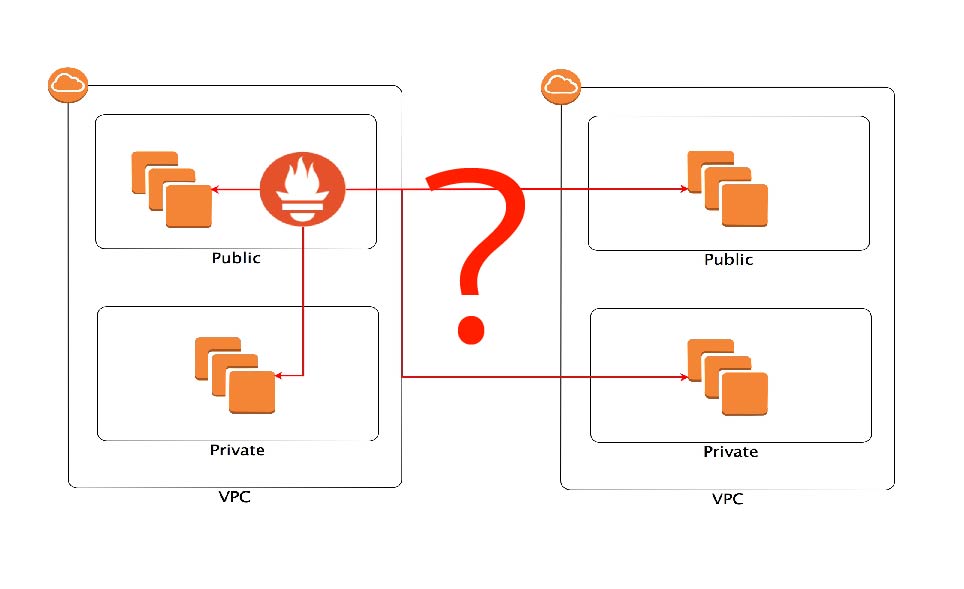
※AWSの環境でご説明させていただくのご了承ください。
こちらについてはPrometheusの公式ページで
下記のように紹介されています。
If an inbound firewall or NAT is preventing you from pulling metrics from targets, consider moving the Prometheus server behind the network barrier as well. We generally recommend running Prometheus servers on the same network as the monitored instances.
Prometheusサーバは監視対象のサーバと同じネットワークに設置することをお勧めしますと。
また既存で紹介されているようなブログ等でもそのようなものがほとんどかと思います。
そこで私は思いました。
「もう一台Prometheusを建てなきゃならないの?」
例えばですが
違うネットワーク環境にあるサーバがたった三台だとしても
その為にもう一台Prometheusを建てなければいけないようです。
「うーん、PrometheusってHTTPプロトコルだし、これってProxyさせて監視取れないかな?」
こう考えた僕はPrometheusの公式ページを隅から隅まで走り回りました。
その時に見つけたのがPushProxです。
※こちらについてはPrometheusのベストプラクティスから外れた内容となっている為
会社の意向や、上長と相談してリスクやメリット・デメリットを考慮した上で導入を検討するべきでしょう。
弊社では僕がNagiosに慣れ親しんでいるという点(NRPEを経由させる方法に少し似ている為)や
一台のPrometheusの運用のみでいいという点を考慮し採用しています。
またこういった状況って少なくないと思っているので1つの手段として紹介させて頂きます!
PushProx概要
PushProxについては下記のOtherに記載があります。
- Prometheus公式:
https://prometheus.io/docs/operating/integrations/
そしてこう記述されております。
Proxy to transverse NAT and similar network setups
お?NAT越えできるんじゃ・・・
そしてPrometheusの公式ページのリンクからgithubに飛び
READMEの記述を確認すると
PushProx is a client and proxy that allows transversing of NAT and other similar network topologies by Prometheus, while still following the pull model.
While this is reasonably robust in practice, this is a work in progress.
” PushProxはプルモデルに引き続き、PrometheusによるNATやその他の同様のネットワークトポロジを横断できるクライアントとプロキシです。 これは実際にはかなり堅牢ですが、これは進行中の作業です。 ”
ありましたね!NAT越えのexporterです!
ですがこちらは記載がある通りプロジェクトが進行中のようです。
弊社では台数の少ない一部環境で使用しておりますが、導入をされる際は十分に検討する必要があるかと思います。
前置きが長くなってしまいましたがPushProxの概要となります。
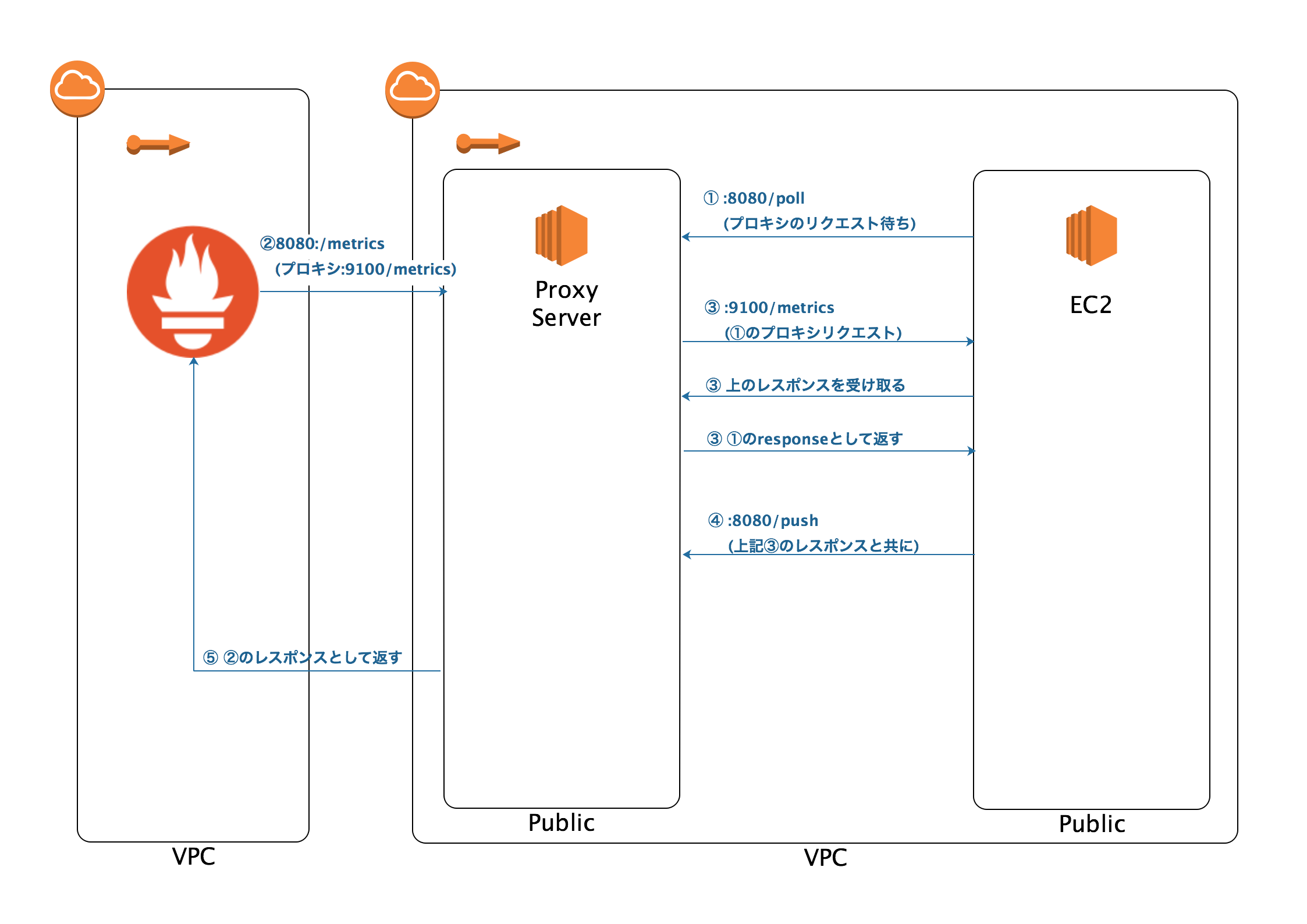
上記の図では
ProxyServerにPushProxのProxy exporterを
EC2にPushProxのCliant exporterを設置しています。
上の図の通りとなりますが
- Proxyサーバの:8080(Proxy exporter)に対してプロキシのリクエスト待ちをする。
- PrometheusがProxyサーバの:8080(Proxy exporter)に対してmetricsを取得しに行く
- プロキシサーバが受け取ったmetricsのリクエストをEC2の:9100に流す
- EC2がレスポンスと共にmetricsをPush
- プロキシサーバがEC2にレスポンスを返す
- プロキシサーバがPushされたmetricsを2で受けたレスポンスとして返す
といった仕組みとなっています。
※分かりやすいようにサーバの部分をEC2として記載させていただいております。
PushProxを実装した場合は監視構成が下記のような形になります。
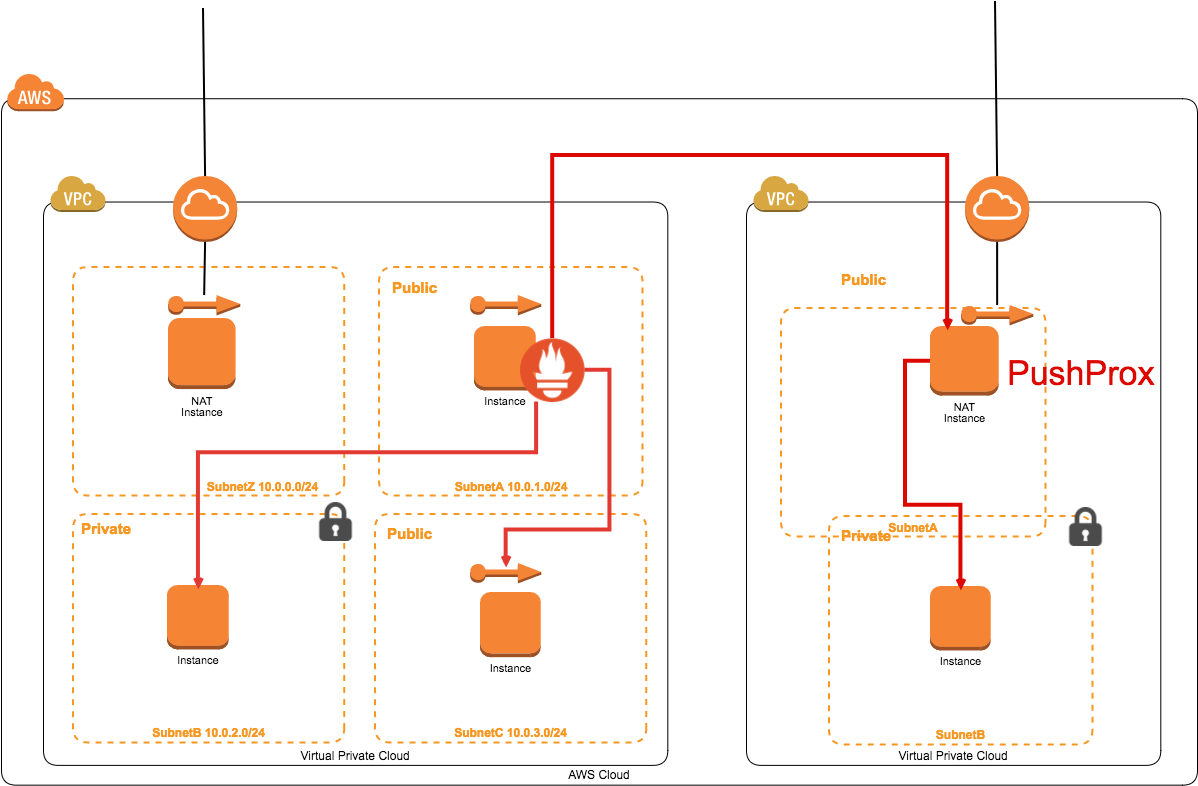
それでは実際にインストールを行ってみましょう。
PushProxインストール
Proxy
$go get github.com/robustperception/pushprox/proxy
$cd ${GOPATH-$HOME/go}/src/github.com/robustperception/pushprox/proxy
$go build
Cliant
$go get github.com/robustperception/pushprox/client
$cd ${GOPATH-$HOME/go}/src/github.com/robustperception/pushprox/client
$go build
これだけです。
1バイナリで動くところがやっぱりPrometheusのいいところだと実感させられます。
それでは設定を行い実際に追加されるのか見ていきましょう。
PushProx設定
Proxy
$ ./proxy
以上!設定というか起動させるだけです。
ちなみにデフォルトでは8080番で受け付けるようになっていますが
-h で確認したところ下記のようになっておりましたので変更を行いたい場合は
proxy [flags]で起動しましょう。
usage: proxy [flags]
Flags:
-h, --help Show context-sensitive help (also try --help-long and --help-man).
--scrape.max-timeout=5m Any scrape with a timeout higher than this will have to be clamped to this.
--scrape.default-timeout=15s
If a scrape lacks a timeout, use this value.
--registration.timeout=5m After how long a registration expires.
--web.listen-address=":8080"
Address to listen on for proxy and client requests.
--log.level=info Only log messages with the given severity or above. One of: [debug, info,warn, error]
Cliant
$ ./client --proxy-url=http://proxy:8080/#プロキシサーバのIP記載
はい。こちら側も特に設定はなくProxyサーバのIPを指定するだけとなっております。
またこちらについても-hで確認した内容を下記に記載します。
Flags:
-h, --help Show context-sensitive help (also try --help-long and --help-man).
--scrape.max-timeout=5m Any scrape with a timeout higher than this will have to be clamped to this.
--scrape.default-timeout=15s
If a scrape lacks a timeout, use this value.
--fqdn="ip-xxx-xxx-xxx-xxx" FQDN to register with
--proxy-url=PROXY-URL Push proxy to talk to.
--log.level=info Only log messages with the given severity or above. One of: [debug, info, warn, error]
Prometheus
prometheus.yml
scrape_configs:
- job_name: node
proxy_url: http://proxy:8080/
static_configs:
- targets: ['client:9100'] # Presuming the FQDN of the client is "client".
ここの部分が少し分かりづらかったのですが
EC2の場合は単に今まで設定していた状態に下記のように
proxy_url:の部分を追加するだけです。
prometheus.yml
- job_name: xxxx
proxy_url: http://xxx.xxx.xxx.xxxx:8080/ ##追加箇所
ec2_sd_configs:
- region: xx-xxxxxxx
access_key: xxxxxxxxxxxxxxxx
secret_key: xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
port: 9100
relabel_configs:
- source_labels: [__meta_ec2_tag_xxxxx]
regex: xxxxx
action: keep
以上で設定が完了となります。
こちらでPrometheusのreloadを行い設定を反映させてください。
またセキュリティーグループやFWの設定についてもお忘れなく。
これでPrometheusで監視対象のサーバが認識されているかと思います!
また冒頭でも記載させて頂きましたが
PushProxはPrometheusのベストプラクティスから外れている内容となっております。
それを考慮の上で導入を検討しましょう。
そしてPushProxの導入を見送る場合はPrometheuをもう一台導入する必要があるでしょう。
お知らせ
次回以降に記載させていただこうと思っている内容については下記となっております。
- alertmanagerでの通知先の設定(サービス単位での通知の振り分け)
- Grafanaを使った描画(CloudWatchやTemlate)
また前回記載する予定のお知らせに書かせて頂きました
init-scriptとログの保存期間については
もう少し掘り下げたいと思っておりますので掲載するか検討中です。
今回も最後まで読んで頂きありがとうございました。
また弊社ではサーバサイドエンジニア、インフラエンジニアの募集を引き続き行っております。
是非一度、話を聞きにいらしてください!