

 Tweet
Tweet
 Share
Share
エンジニア組織としての監視文化の作り方
Nagisa インフラエンジニアの榎戸です。
今回は僕が入社してから一年が経ったので、
僕が感じた事とやってきたことを監視に絞って書きたいと思います。
※また今回は技術的な内容についてはあまり触れておりませんのでご了承ください。
入社時の状況
今ではかなり改善できたので笑い話となりますが
当時(昨年9月)はなかなか言葉には出しづらい状態でした。
当時の状況
- 監視はCloudWatchに数個
- Nagiosとmuninが監視の役目を果たさず稼働している
- 監視の重要性の認識不足
- 障害が起きてから数時間後に気付く
- 障害対応をすると感謝されながらランチに連れて行ってもらえる
こんな状態でした。
インフラエンジニアとして入社したのに
障害対応をするとランチに連れて行ってもらえる
という体験には驚きと動揺が隠せませんでした。
今まで当たり前だった障害対応ですが
お礼を言われたのは初めてでしたし
この会社には組織として他人への感謝がしっかりできる組織なのだと感じました。
ただこれは障害対応を行った結果のご褒美であり、
障害の原因についてはひとに焦点が当たってしまい、
そのひとの責任となってしまうような状況もありました。
僕はこれらの状況についてまず最初に
監視 = 文化として浸透させなければならないと感じました。
障害が起こってしまうのはひとが原因ではなく、
仕組みが原因であり、文化が原因であると考え、
組織全体で解決していく文化を作っていく必要がありました。
障害が起きるのは誰も悪くありません。(例外はありますが・・・)
そして今までの状況についても、
監視という文化がなかったというだけだったのです。
文化としての監視/Nagiosの導入
ではどこから手を付けていけばいいでしょうか。
ここからは文化として浸透させることを考えながら、
これまでに僕が行ってきた取り組みについて書きたいと思います。
まず最初に下記の記事でも記載しております様に、
弊社では僕の前提知識があったのでNagiosを導入しました。
https://blog.nagisa-inc.jp/archives/1405
とにかく監視を始めてみるというのがとても重要だと考えての判断でした。
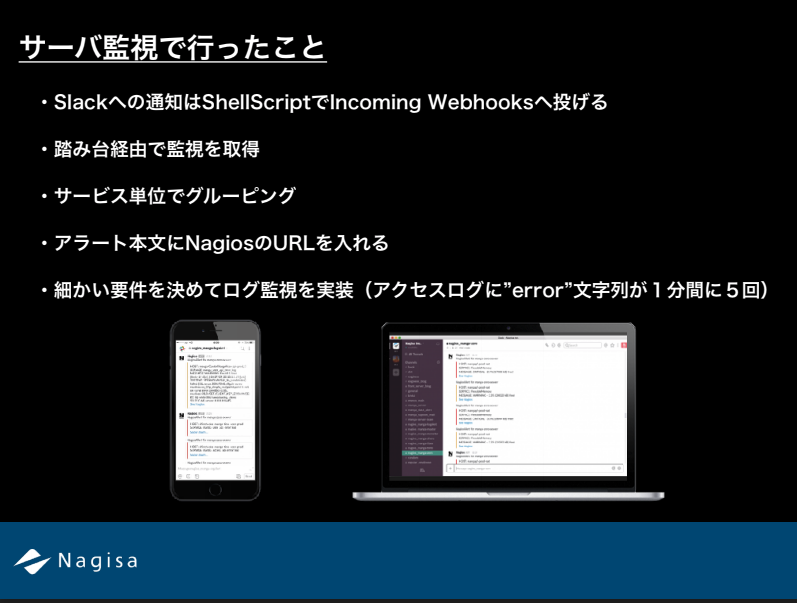
まずNagiosを導入するにあたってサーバサイドエンジニアに監視でどんな事が実現できるかを説明し、
必要な監視項目を一緒に洗い出して頂きました。
また社内のLTでも監視の役割と重要性について発表させて頂きました。
こんな感じのスライドを数枚で発表しました

そしてNagiosの構築が完了し監視体制自体は整ったのですが
下記の問題が浮上しました。
- アラートはスルーされがち
- 対応はほとんど自分
- なかなか監視について興味をもってもらえない
- アラートに対する共通認識の不足
この時に初めて監視 = 文化として浸透させる難しさと導入するべき技術について考えました。
文化としての技術選定
まずNagiosはとても扱いやすく、かつ監視に関しては大体のことができるとても素晴らしい監視ツールだと思います。
※各種監視ツールの技術的選定基準については下記で記載しております。
https://blog.nagisa-inc.jp/archives/1405
ですが組織の文化として浸透させることを考えるとNagiosは少々
他のエンジニアたちの関心を集める部分が足りなかったのではと感じています。
それではどのような監視ツールであれば組織の文化として
浸透させることできるのでしょうか。
こちらを考える際には下記を基準としました。
- 他のエンジニアが見ても分かるものかどうか
- 弊社での開発言語と合っているかどうか
まず他のエンジニアが見ても分かるものかどうかですが、
これが導入にあたって結構大事な要素になっております。
一概に監視といっても様々な意味を含み、
ただ死活監視やリソース監視を行うだけであれば、
ここの部分は正直必要ではないと感じております。
ですがパフォーマンスを意識した開発体制を提供することを前提とすると、
開発者側にもわかりやすく、かつ改善結果がすぐにわかるものがいいと判断し、
この結果ビジュアライズできることが1つの選定基準となりました。
また弊社での開発言語と合っているかどうか
についてはそのまま組織の文化と直結しており、
開発者が使用している言語と監視ツールの親和性が高ければ、
導入後の機能追加の相談などがしやすく、
さらには学習コストも低いと考え、
GoもしくはPHPとの親和性が高いものを選択するのが望ましいと考えました。
弊社では上記文化と技術の両方を踏まえた上で選定したのが
Prometheus + Grafanaです。
Prometheusの導入
では実際にPrometheusを導入してみてどうだったかというと、
最初は僕にとって新しい監視ツールであった為大変でしたが、
最近ではPrometheus + Grafanaを導入してよかったなと思う部分が出てきました。
まず弊社の場合Prometheusを導入してよかった点としては、
先ほど記載した弊社での開発言語と合っているかどうか、という部分でかなりの恩恵を受けられていると感じております。
PrometheusはGo言語で開発されており、弊社でもGo言語を使用してサービスの開発をおこなっております。
なのでGo言語のパフォーマンス監視を行う際には簡単に導入することができました。とサーバサイドエンジニアが申しておりました。
またGrafanaを合わせて使用することによりビジュアライズにおいて、
かなりの恩恵をうけることができています。
先日リリース致しましたマンガZERO web版のAPIはGo言語で開発をおこなっているのですが、
こちらのパフォーマンス監視に使用しており、メモリリークが起こってしまった際もいち早く気づくことができ、
Grafanaの画面をサーバサイドエンジニアに一緒に見てもらいながら改善していくことがきました。
その時のグラフです。
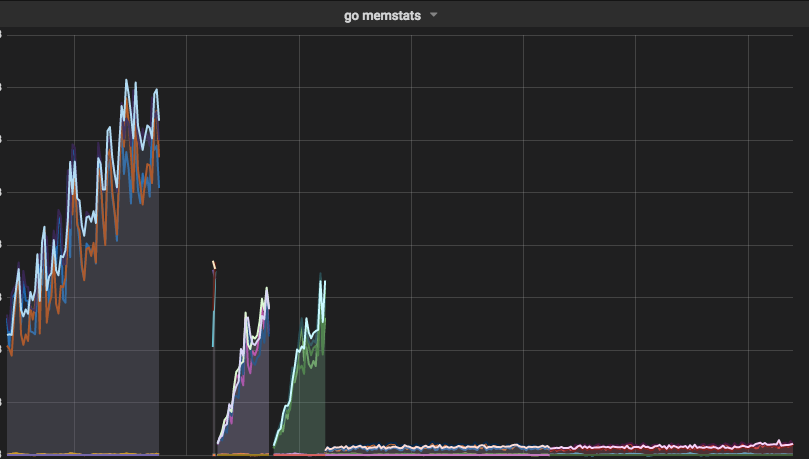
かなり改善されているのが一目瞭然です。
またPrometheusは通常の監視エージェントのみでも、
かなりのリソースを監視できるため、こちらでも十分メモリリークなどには気づくことができます。
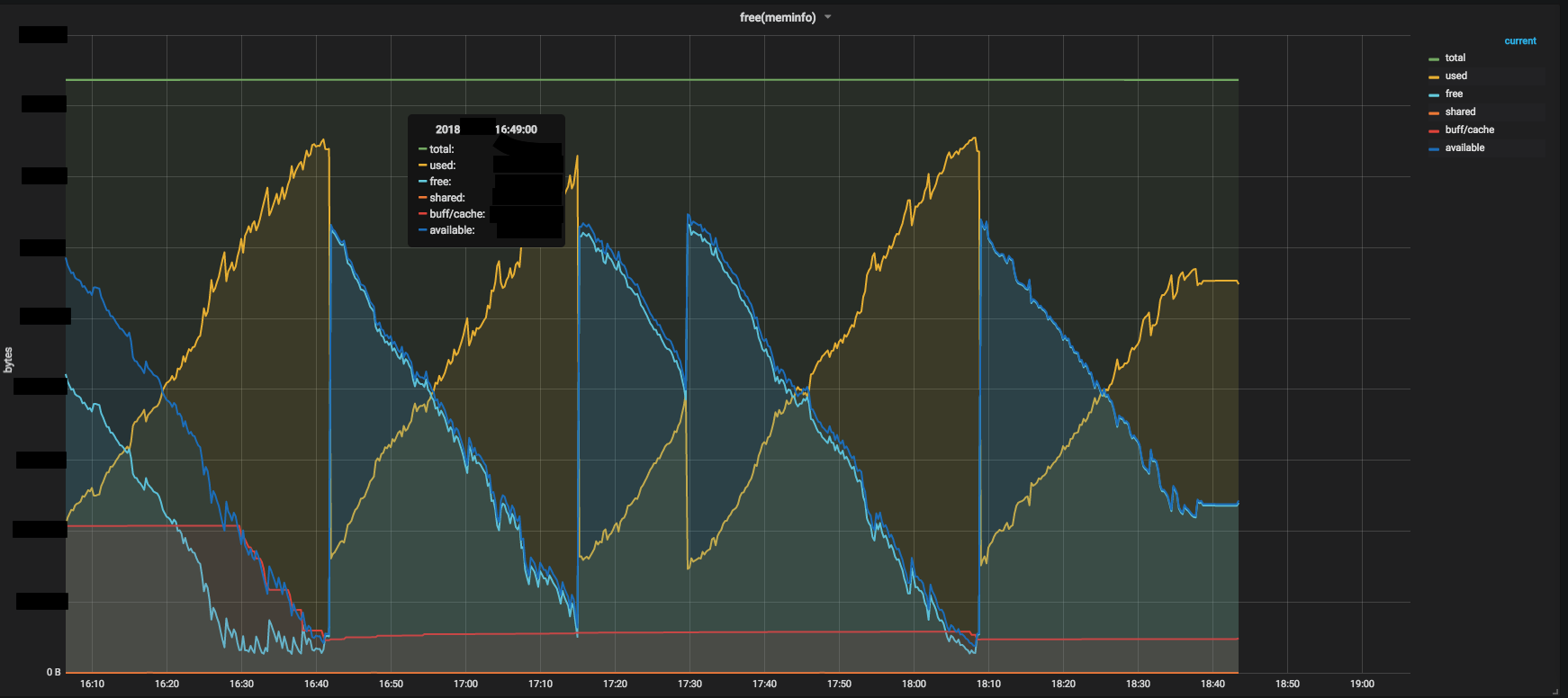
例としてデフォルトの監視エージェントでもフロント側で起きてしまったメモリリークに
早く気づくことができ、フロントエンジニアと一緒にGrafanaを見ながら改善できました。
その時の様子です。
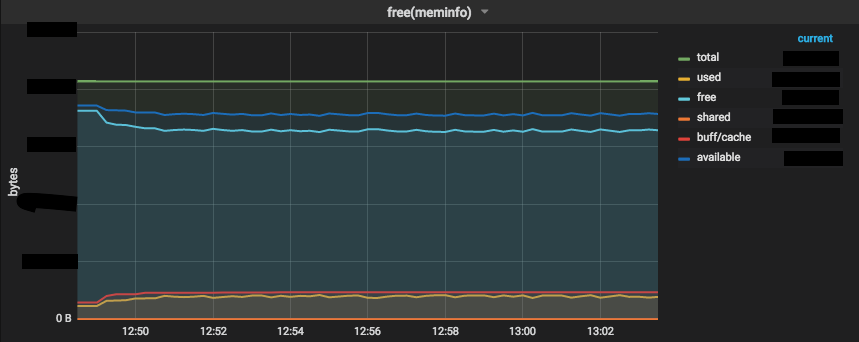
そして改善した後のグラフはこちらです。
そしてこれらはStage環境にも導入している為、
検証を行いメモリリークなどの問題が起きていないか、
フロントエンド,サーバサイド共に自身でGrafanaの確認を行ってから、
リリースを行っているので、安定して開発フローを回していけているのではないかなと感じています。
まとめ
これらの経験を通して、導入するツールを選定する際には
大きく分けて下記を基準にしています。
- 技術面でどのように問題を解決できるのか
- 他ツールとのメリット、デメリットの比較
- コミュニティが活発かどうか
- 組織の文化として浸透させていけるか
- 組織の開発言語と親和性があるか
- 他のエンジニアも一緒になって運用していけるものか
もちろんこれ以外にも重要な要素はあるかもしれませんが、
技術と組織の文化のどちらも僕自身は重要だと考えており、
このような基準で選んでいくことによって
責任の在処を仕組みや文化に置くことができますし、
問題が起こった際にはこれらの仕組みや文化をエンジニア同士で修正していく、というのが良いかと思います。
また弊社の監視環境においてはまだまだ出来ることがたくさんあるので、
より突き詰めていければと思っておりますし、もっと組織全体として使用していけるように
さまざまな監視項目の追加などを行っていければと思っております。
そして弊社では一緒に開発を行ってくださるエンジニアを募集しております。
気になった方は是非ご一報頂ければと思います。